Recently I watched “Jodorowsky’s Dune”, a documentary about an epic science fiction film that was never made.
Alejandro Jodorowsky, an infamous Chilean abstract writer-director, decided to film the science fiction masterpiece “Dune”. The scope of the project was immense, as evidenced even by its opening shot: zooming in slowly from outside the galaxy, passing space battles, pirates, spice freighters, stars and planets, until finally settling on the planet Arrakis.
Here are some of the people who were signed on to the project:
Orson Welles
Mick Jagger
Salvador Dali
Dan O’Bannon (writer of “Alien”)
H.R. Giger (character designer of “Alien”)
Soundtrack by Pink Floyd
and many others…
The storyboard, and much of the concept art, was created by Jean Giraud “Moebius”, one of the greatest graphic novel artists of all time.
There are many lessons I took away from the documentary. About overreaching with ambition. About the struggles of the creative process. About vision and leadership and team-building. About excessive sacrifice (Jodorowsky literally gave his son to the project, by pulling him from school and bringing him up as the character Paul he was to play). And about dealing with the loss of a creative dream.
But there is one idea, far more practical, that has been rolling around in my mind since watching the film. And it’s this:
Why are there no professional concept animators for software?
I’ve been balancing a number of things over the past few years, and continue to do so. Yet I’m reaching a point where it no longer feels overwhelming. It’s taken me a long time to get to this point, but recently I looked up from work and realized, “I’m on the right path. I got this.”
I’m finding my flow, and it’s been worth all the struggle to get to this point. I can work on Gingko, and make tangible progress, while not letting any balls drop. I can help my wife, part-time, with her skincare business (everything from logistics, to design, to IT). I can go for walks with my son, do laundry, groceries, read. Spend time with friends. Take time to think things through.
Some have said that I’m “doing it all”, but I want to state emphatically, that the idea of being able to “do it all” is damaging.
In fact, “doing it all” is the primary enemy of a balanced life.
We don’t have a medium dedicated to working at the boundaries of knowledge. Such a medium would be immensely powerful for advancing science, education, and governance. It would change the way people live and work.
What we need is a vast, dynamic, collaborative tree structure.
An Example: Unbounded Work and Play
You are a software developer, and though you currently work on writing back-end code for a few clients, you have a constant interest in High Performance Computing.
After you finish your work for the day, you log in to the Tree. In the Tree you are classified as an expert in large-scale galactic simulations. This classification is based only on the work you’ve done in the Tree; not on your age, your location, your language, or your “formal” education.
Because of this, you have a custom feed of “issue nodes” that might fall in your domain. In scanning the issues, you find one titled “Need to run Monte Carlo simulations of galactic rotations, using Hydrodynamics model.”
You’ve done something similar in the past, and though you used a far simpler model for the forces, you are quite sure the basic structure of your code can be applied to this. A quick dive into that issue branch, and the overview nodes tell you that yes, your code could help. You find the root node of your own simulation source code, and drag it onto this issue.
The person who opened that issue might be a PhD student at Brown University, an honours undergrad in Romania, or a bright home-schooled girl in South Africa. In any case, a copy of your code is now attached to their issue, and you probably saved that person hours or weeks of work with one click.
In turn, you’ve been playing with different models of galactic rotation, to see if you can find an alternative to the Dark Matter theory that explains the anomaly (which is listed as a top-level issue in the Astrophysics subtree). You’ve opened your own small issues in your own notebook subtree when you’ve gotten stuck on the physics, and within a few hours received the solutions. You thanked the senders with a click, and kept playing with the code.
Your work might turn up little, but it’s a fascinating area to explore. Still, your account balance from your contributions and solutions has been increasing steadily; it seems experts in simulation are in demand, and soon you’ll be able to devote yourself full-time to working on the Tree. Maybe later you’ll try your hand at molecular biology, another simulation-heavy field where your growing expertise can make an impact.
How, when, and what you choose to contribute to is up to you, and you are free to explore, play, learn, and work in whatever area you like.
The Tree that makes this possible
It’s not a new idea that we need a “GitHub for Science”. However, it’s a mistake to assume that the medium for this will look anything like GitHub.
I think it will look something like this:
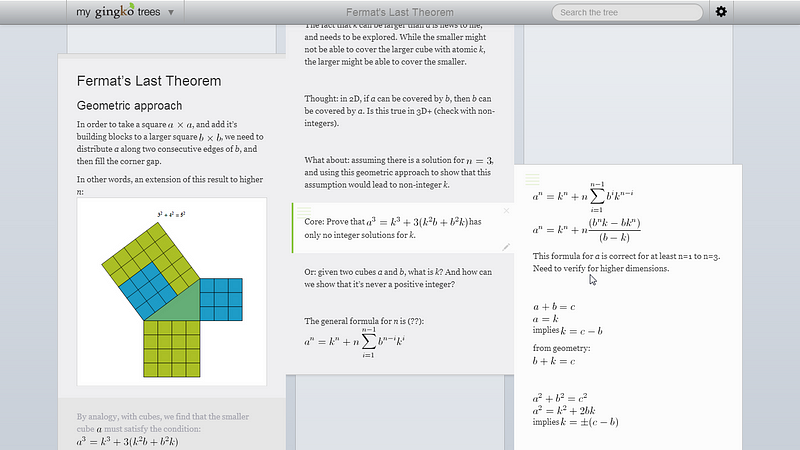
A gingko tree of someone tackling Fermat’s Last Theorem.
Trees like this are easy to browse, provide constant context, have no disconnected elements, and can go arbitrarily deep.
Self-similarity & Constant Context
Trees, in the idealized sense, have perfect self-similarity. Whether you are reading an overview of the current open questions in Physics, or the particular experimental details of one botanist, the medium is identical. Only the content and the particular branching structure is different.
Once you take the 30 seconds to learn how to navigate one tree, you can navigate the entire tree of knowledge. There are no link trails to follow, no citations to parse and search for. The entire skill of searching through scientific literature, which takes years to develop, is reduced to using the four arrow keys.
A child could do it.
And, I hope, many will.
While it may seem that the scale of this tree would make this effortless browsing impossible, there are two important points that make this medium feasible.
First, you can and will search for a starting point that you already understand.
Second, in navigating this information, you are always going to be exposed first to a broad overview of any given field, before diving in. At each step, you see the context, which helps guide and inform your path through the deeper levels of the tree.
This not only makes it easier to learn entirely new areas, it also helps you bridge over into neighboring disciplines.
Finally, the uniformity of the tree structure could be used to keep discussions and open questions right there next to the research being done, in context. Learning will no longer be about static facts in a textbook (or Wikipedia page), but a dynamic process the way science is really done, full of exciting unanswered questions.
Unlimited Depth Opens Up the Medium
Current science happens at one level of detail, restricted by the archaic medium of paper (or the modern version, PDFs or static HTML, which are only slightly better).
In general, a graduate student will work for years on a given project, and eventually crop this work into a few hundred pages of a static thesis. And then crop it further to a few pages of static text & images.
What happens to all the source code? The raw data? The unfinished work, the unexplored areas? The dead ends? These often amount to months or years of work. Work that needs to be redone from scratch by anyone following in your footsteps.
If you work in a deep tree structure, there is never any reason to discard anything. You can always reorganize your notes, summarize them. Your notes can become your thesis. With some more summarizing and organization at a higher level in the tree, your thesis becomes your paper. And paper, thesis, notes, and source are all linked together and organized in a way that makes it easy for others to understand.
There is another illusion, more subtle, that the current medium of science perpetrates: that work is ever “done”. This illusion is brought about by the act of publication. Something is either unfinished, unpublished, and therefore invisible, or it is published and static.
By allowing for infinite depth, we are allowing for more information to be added in context. And we are also removing the distinction between a researcher’s notebook, and his “published” work. Or, in a sense, we move to publishing people’s living dynamic notes, complete with doubts, unanswered questions, and unfinished work.
This might be a terrifying prospect for some, but that’s an artifact of the reward systems in place now, and is heavily outweighed by the benefit: working this way turns all science into massively collaborative open-notebook projects.
Other benefits
There are a number of other benefits that come from this approach. A relatively minor one: scientists no longer need to paraphrase and rehash the same introductory paragraphs everyone in their field uses… by attaching their paper to the relevant node, layers and layers of introduction and overview are provided automatically.
This Tree of Knowledge would also have a larger effect on education. Instead of testing, we can let students of all levels try to make a contribution, however small, to the Tree. Why must we go through 15-20 years of school before we’re allowed to contribute even a single word, a single question even, to the living body of human knowledge?
Challenges
The technical challenges of maintaining such a large seamless structure are quite significant. Also, I am not naive enough to think that a single pure hierarchy can contain all of human knowledge & current research. We need to consider how to handle transclusion (i.e. “symbolic links”), whether or how to handle circular references, etc.
There is also the challenge of maintaining Quality and a good signal-to-noise ratio. Wikipedia has shown that this is a surmountable obstacle.
But I think by far the greatest challenge is not technical, but psychological. Besides the fear of working out in the open, we must also recognize that science employment is based on authority, and authority comes from publishing papers in prestigious journals.
If we entirely remove the publication process, how are scientists to be ranked, hired, and paid? Algorithmic ranking based on Tree contributions? Perhaps funding can be applied to “branches” of science quite literally, and the rewards distributed through the subtree? Maybe we would use anonymous peer ranking? Flattr type rewards?
In any case, it is a challenge, and one that will need a solution. But solving it is not insurmountable, and will have more to do with behavioural psychology than with technology.
The road ahead
At the moment, the use of trees to work with text and images is very new. Mindmaps have done this for a time, but are focused on recall & consolidation. Outliners are focused too much on the structure of a body of work, and are not good at displaying the content.
Our own Gingko word processor is, I believe, a small step in the direction we need to move towards. Structure and content are seen at the same time, the context or overview is always in view, and the content can be extended to contain not just text & images, but also source code, data, dynamic graphs.
If the sum of human knowledge were a book, we already have Google as its index, and Wikipedia as its glossary. What we need now is a tool to serve as the blinking cursor, where the real action is.